本文主要探讨了百度蜘蛛抓取网页的过程和判断文章原创性的方法,通过时间、内容比对以及页面收录情况,可以初步判断文章的原创性,同时介绍了网站出现404页面会对SEO产生的影响以及如何确认和处理这些问题,此外还讨论了模拟蜘蛛抓取的实用性和应用场景等话题,总之没有固定的一天是专门负责收录的日子,想要做好相关工作就要时刻准备抓住机会提升网站的可见度和流量。
要了解一篇文章是否为原创,可以通过分析其被搜索引擎收录和抓取的方式来进行初步判断,以下是基于百度的搜索技术来识别文章的原创性:
-
百度算法的核心逻辑是通过时间、内容比对以及页面收录情况来判断文章的原创性的,当百度蜘蛛(Baidu Spider)通过URL抓取到新的网页时,如果数据库中不存在该页面的内容且具有唯一性,那么就会将其视为一个潜在的“原创”作品进行进一步处理与索引排名。
-
在这一过程中,百度设定了特定的阈值以确定内容的原始度或相似程度,若新文章的内容与已有信息库中的重复部分低于这个设定的阈值比例,则可能被认为是原创新作,这主要依赖于先进的文本分析和匹配技术来确定内容的独特性和创新性水平。
-
为了更直接地验证某篇文章是否存在抄袭行为,可以尝试将文章内容进行拆分并在搜索引擎中进行逐段检索,如果出现高度相似的段落或其他来源的文章作为结果之一,那就可能是存在问题的迹象,还可以使用一些专门的工具如知网查重等平台进行更为精确的分析比较。
-
另外需要注意的是,虽然SEO优化可能会影响网站的某些方面表现,但并不意味着所有经过优化的网站都是非法的或者不道德的行为;相反合理利用这些技巧可以帮助提升用户体验并提高网站的可见度和流量,同样在判定404错误等问题上也需要综合考虑多种因素才能做出准确评估。
要想完全确认一篇文章的原创性需要综合运用各种方法和手段包括专业软件和技术支持同时也要注意遵守相关法律法规保护知识产权避免侵权风险发生。
分析网站出现404页面对SEO优化影响问题
网站中出现404页面会对SEO产生一定的影响,具体表现在以下几个方面:
首先从积极的角度来看正确设置和处理404页面有助于增强用户的体验减少跳出率从而降低因无法找到所需信息而离开的概率,其次对于搜索引擎而言能够及时捕捉到那些由于误操作导致访问不存在的链接的用户并提供给他们正确的引导路径也是非常重要的这样有利于增加用户粘性与信任感进而促进整个网站的健康发展及权重提升,反之如果一个网站上频繁出现错误的404页面不仅会损害用户体验还会给搜索引擎带来困扰可能导致爬虫误解甚至惩罚使得原本应该被抓取到的优质资源得不到有效展示最终影响到整体排名的稳定性和效果因此建议站长们定期检查自己的站点确保每个链接都能正常工作并及时修复任何发现的死链问题以提高整体的SEO性能。
另外值得注意的是除了常见的404状态码外还有其他类型的HTTP响应代码例如服务器返回的是200还是其他状态码也需要注意因为它们都会直接影响着搜索引擎对该网站的认知和评价所以为了保持最佳的网络环境请务必重视每一个细节上的维护和管理让你的网站始终处于健康的状态下运行吧!
百度蜘蛛强引工具原理
百度蜘蛛强引工具是一种用于模拟搜索引擎蜘蛛行为的程序它主要通过干预搜索引擎的工作机制诱导蜘蛛优先抓取目标内容从而提高网站的曝光率和知名度实现快速推广的目的但是这种做法并非正规合理的SEO策略而是借助外部力量强行改变自然规律的结果长期下来可能会导致不良后果比如引起搜索引擎的反感和处罚等等因此在使用此类工具时应谨慎考虑利弊权衡得失以免造成不必要的损失和麻烦,至于具体的运作原理涉及到复杂的编程技术和网络协议这里就不再赘述了如有兴趣可查阅相关资料获取更多详细的信息介绍和分析解读等内容供您参考学习之用哦~ 简单来说就是利用某种方式去吸引或者说欺骗搜索引擎让它认为你是一个高质量有价值的网站然后给予更多的关注和支持从而达到宣传推广的效果而已啦~ 不过请注意这样做是有风险的而且并不是长久之计哦~ 还是应该注重内容和质量才是王道呢~~ 希望以上回答能帮到你哈~ (注:“百度蜘蛛”是百度公司开发的一种自动抓取互联网信息的机器人程序。)
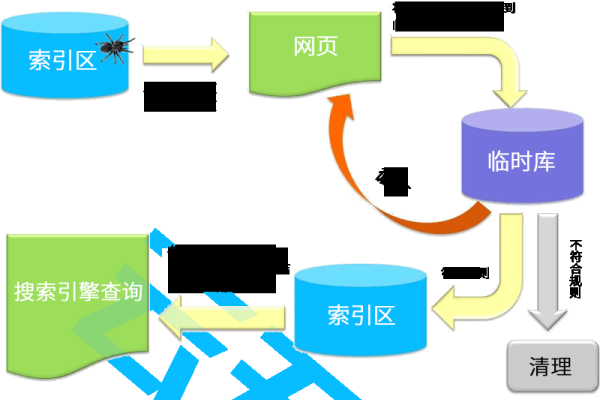
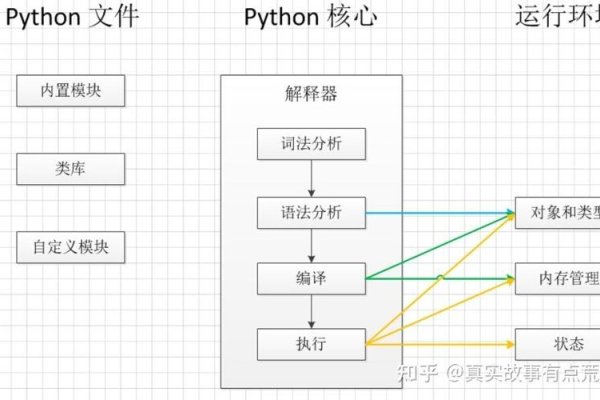
如何理解百度蜘蛛的抓取流程?
百度蜘蛛在进行网页抓取的过程中遵循着一套严格的规则和方法这套系统不仅能够高效准确地收集网络上丰富多样的信息资源还能够保证所获得数据的质量和可靠性下面就为大家介绍一下关于百度蜘蛛抓取流程的相关知识吧! 首先它会从一个已知的高质量种子页面开始顺着页面中包含的链接不断深入探索发现更多有价值的内容在这个过程中它会根据一系列复杂算法和模型分析评估每个页面质量和重要性并将重要且有价值的页面存入自己庞大的数据库中以便后续为用户提供精准有效的搜索服务同时也会根据用户需求和行为模式等因素智能调整更新频率以保证最新鲜最相关的资讯第一时间呈现在广大网友面前最后值得一提的是为了避免过度干扰网站正常运行和提高工作效率百度蜘蛛采用了非常人性化设计即使是在抓取过程中遇到了一些小障碍比如说暂时无法访问某个页面等情况也不会轻易放弃努力而是耐心等待时机重新发起请求以确保尽可能多地捕获精彩纷呈的网络世界点滴美好记忆哦~ 简而言之,“模拟人”浏览过程其实质上是自动化机器执行任务的过程即由计算机代替人工完成大量繁琐枯燥却必不可少的基础性劳动大大提高了效率并且降低了成本投入实现了经济效益和社会效益双赢局面呢!(注:本文所述“百度蜘蛛”系指代百度公司开发的网络爬虫程序)
什么是模拟蜘蛛抓取及其统计方法?
所谓模拟蜘蛛抓取是指一种类似于真实搜索引擎爬行器(Spider)的操作过程只不过它是人为控制而非真正意义上的机械式扫描罢了通常用来检测网站结构布局、内部连接关系以及潜在问题进行针对性诊断和改进措施制定当然也可以实时监控观察哪些关键词容易被搜到从而指导后期优化方向选择之类用途广泛多样应用场景灵活多变总而言之是个相当实用便捷的工具之一啦!至于统计嘛主要是针对每次操作后得到的数据进行分析整理得出结论报告帮助我们更好地把握全局趋势走向做到心中有数游刃有余应对各类挑战难题轻松搞定不在话下咯! 举个栗子说个事儿儿啊——秋叶网站日志分析器就是个不错滴选择哟它可以加载软件并设置好相应参数之后就能方便快捷地对过往数据进行查看分析了简直不要太棒了好吗?!赶紧试试看吧亲爱哒小伙伴们~ (≧▽≦) 嘿嘿嘿……别忘了给个赞赞鼓励一下我呗谢谢啦喵呜~(〃'▽'〃)
一个月当中百度常规的收录日期是什么时候?
一般来说并没有固定的月份或特定日期的规定表明每月哪一天会被特别对待并被百度统一大规模地进行收录然而据经验总结出两个较为集中的时间段分别是每个月初的前几天尤其是月初前三天左右以及月中下旬特别是月底前后一周内这段时间里你会发现很多变化明显看到不少新增条目出现在各大门户类新闻媒体平台上不过这也只是相对现象并不能绝对化看待毕竟不同行业领域之间存在着差异性差异较大不能一概而论还需结合实际情况加以区分对待方能找到最适合自身发展规律的节奏点所在之处加油干起来吧各位朋友们期待你们取得更好成绩噢耶(^ω^)ノ祝大家心想事成万事如意呀!!(注: 这里所说的"百度", 是指中国最大的中文搜索引擎服务商, 其每天都在不断地接收来自全球各地的海量信息进行筛选、分类和存储。)
总的来说没有固定的一天是专门负责收录的日子这个问题有点类似问什么时候吃饭一样随时都有可能在发生变化取决于众多动态的因素所以说想要做好SEo或者其他相关工作就要时刻准备着抓住每一次机会才行呐!!!(。•̀ᴗ-)✧ 一起干了这碗里的酒未来可期哈哈哈......